
Tutorial - Sample Statistics and Accuracy Assessment Tool
This tutorial introduces the user to working with Sample Statistics and the Accuracy Assessment tool within eCognition Developer to apply a supervised classification on an satellite image. The goal is to create a Land Cover Classification based on samples and also determining the accuracy of the resulting classification.
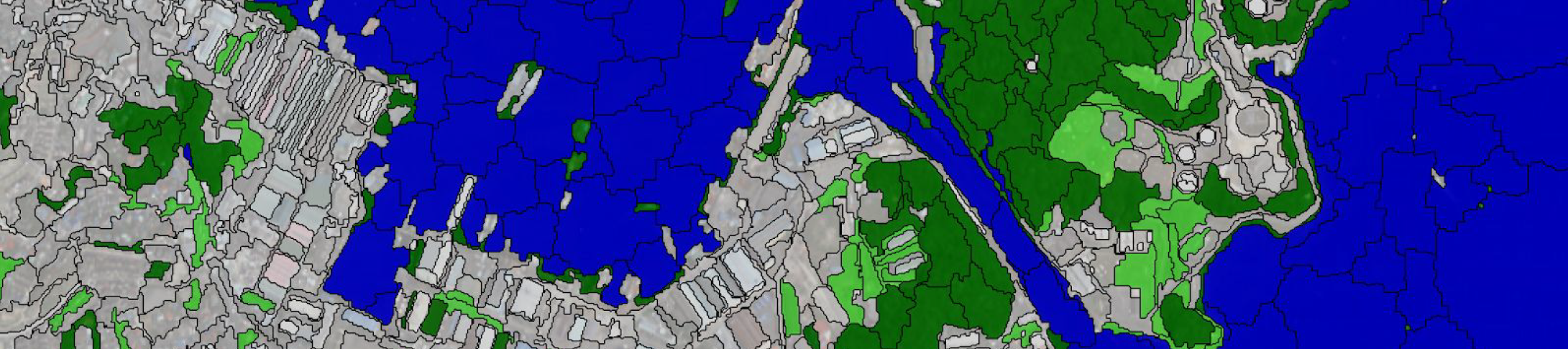
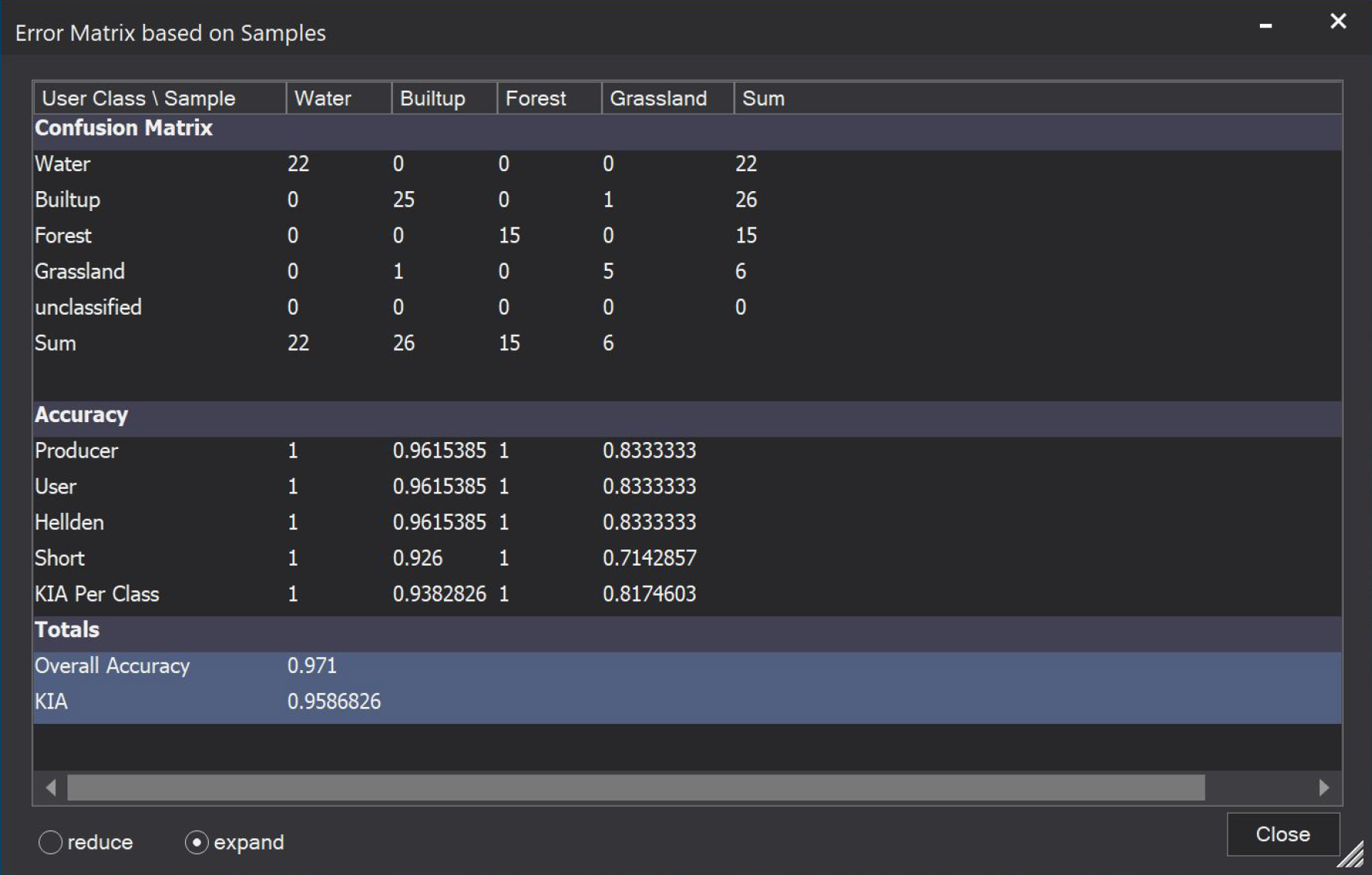
You will learn how to use samples that are available as a shapefile (Samples_training.shp) and how to convert them to sample statistics which then will be used to train a supervised model (and apply it). Furthermore, you will also learn how to do an Accuracy Assessment based on information stored in a shapefile (Samples_validation.shp). The ‘Accuracy Assessment’ tool generates a typical error matrix that computes the user’s and producer's accuracies as well as kappa and other useful statistics related to the accuracy of the classification.
For questions that may arise during this tutorial, please consult the online help or the offline help documents: ReferenceBook.pdf or the UserGuide.pdf. In addition, you can also refer to the eCognition Knowledge Base.
Further information about eCognition products is available on our website: www.eCognition.com.
The tutorial was created using eCognition v10.0 and needs to be updated. For the use of Sample Statistics, please download this project created using eCognition Developer v10.2 explaining the basic workflow with version 10.2.

Was this article helpful?
14 comments
Your Answer
Articles in this section
- Segment Anything (SAM) AI Model Now Available in eCognition
- From the Ground Up - Getting Started
- From the Ground Up - Supervised Classification
- From the Ground Up - Accuracy Assessment
- From the Ground Up - How to create a DSM, DTM & nDSM
- From the Ground Up - Working with IOL hierarchies
- From the Ground Up - Working with Regions
- From the Ground Up - Change Detection using Maps
- From the Ground Up - Startrails
- From the Ground Up - Deep Learning
I wanted to complete this tutorial but I'm having some trouble finding the tutorial datasets Where can I download them?
Download should work again.
Hi Matthias, I'm using the trial version which of course prevents opening workspaces or projects. Do you have a version where you expand the ruleset or with screenshots of all the algorithm windows? Thanks, your tutorials are excellent.
Hello, Matthais, I am using version 9.4. Is there a way I can generate a shapefile for my personal project just like the way you have it there.
I only have the exported TTA Mask which is just a csv file and not shp
@ Anna: Good point actually! I added the Rule set to the .zip folder. Those you can open in the trial version. We will try to create a video tutorial on this till end of February. Looking forward to get your feedback on that ;).
@Seyi: You can use the manual editing tools to create a vector, or you can use the "convert image objects to vector objects" algorithm to create vectors based on objects.
Hope that helps?!
Cheers,
Matthias
Thanks for the updated tutorial and example ruleset Matthias. Looks great. I was successful training and test at one site and then saving the sample statistics and applying to another site. A really cool approach!
Thanks, Matthias! I am able to load most of the ruleset. Unfortunately, no exports are allowed from the trial version so the "export supervised sample statistics" algorithm cannot load, so I don't have a sample statistics csv file to use for classification. I read through the tutorial and I understand the concepts and algorithms used. I'm excited to try this when I purchase the subscription. Thank you!
Thanks, Mathias.
I would like to ask if there is a way I can export selected training samples as shapefile and not TTA files (csv).
Yes, you will need to convert these to classified image objects and then export as a vector file (incl. SHP) with a standard export algorithm.
Thank you very much, Keith.
However, anytime I export the vector file, it exports the entire objects (gotten from image segmentation) whereas I just need the vector file for the selected objects(i.e the training samples).
You need to define the classes of the image objects to export in the "Domain" section of the algorithm.
Hi again Matthias! I am working with my own data and incorporating the algorithms in this tutorial successfully, including the use of training and testing samples as thematic layers to create sample statistics. I would like to improve the classifier (I'm using SVM) so I have tried a couple of things: I increased the sample size for both training and testing samples (using Generate Random Points in ArcGIS Pro), which helped my accuracy somewhat. Also, following classification, I then used the Thematic Editing in the Manual Editing Toolbar to add both training and testing points to those respective thematic layers, which are used in the sample statistics algorithm. This is obviously not random. I was wondering if you'd recommend this second workflow or if it should not be considered a "best practice" due to the influence of the developer (me) on the choice of sample points. I can also go in and manually edit the classified objects following the SVM classification, but I wanted to experiment with the sample set and developing sample statistics so I could make this as automated as possible. Thoughts? Thank you!!
Hi Anna,
First, you can create / select random objects also in eCognition ;) Have a look at this video --> https://youtu.be/FvrCzssXsdw. It was recorded with the older version of eCognition, so the interface looks different, but overall the showed workflow should work fine. I think I also show how you can split your vector into 70/30 calibration / validation.
In my experience it is more important to have good samples at some point instead of increasing the sample size. Maybe also splitting a class into two could make sense at one point, if they are representing the same but are spectrally totally different (buildings with red roofs compared to buildings with blue roofs).
Hope this helps?!
Cheers,
Matthias
What is the Short Value? Ive identified its definition in the user guide but Id like a little more explanation on what it is and where it came from. I have not seen this term in academic literature, is it a proprietary metric with eCognition or does it have a different name elsewhere?